
Google Torah?
In an age of super powerful artificial intelligences, will we be able to trust machine translations of our most sacred texts?
May 13, 2020

Tablet Magazine

Machine translation has made incredible advances, as anyone who has copied and pasted a foreign block of text into Google translate can attest. It still can’t compete with a human translator but sometimes it is good enough: if one does not care about literary merit, if the source text is sufficiently simple or artless, if one needs a poor translation now rather than a better translation later (or never). Soon, algorithms doing “good enough” translations of newspapers and magazine articles will compete with human translators, promising to do in seconds what had formerly taken hours, and at next to no cost. The next inevitable step will be for the curious and the faithful alike to apply machine-translation engines to sacred texts. But can an algorithm really be entrusted, even in a technical capacity, to render the word of God or, for that matter, the word of Proust or Shakespeare? That answer depends, in large part, on how we understand the act of translation and the creation of meaning.
Let’s start by looking at how Google takes on Psalm 1. The standard translation from the ancient Hebrew is: “Therefore, the wicked shall not stand up in judgment, nor shall the sinners in the congregation of the righteous.” Google’s proprietary artificial intelligence (AI) for translation, which knows far more modern Hebrew than ancient Hebrew, delivers this translation: “Tool inaccurate in judgements and inquests in sidecars.”
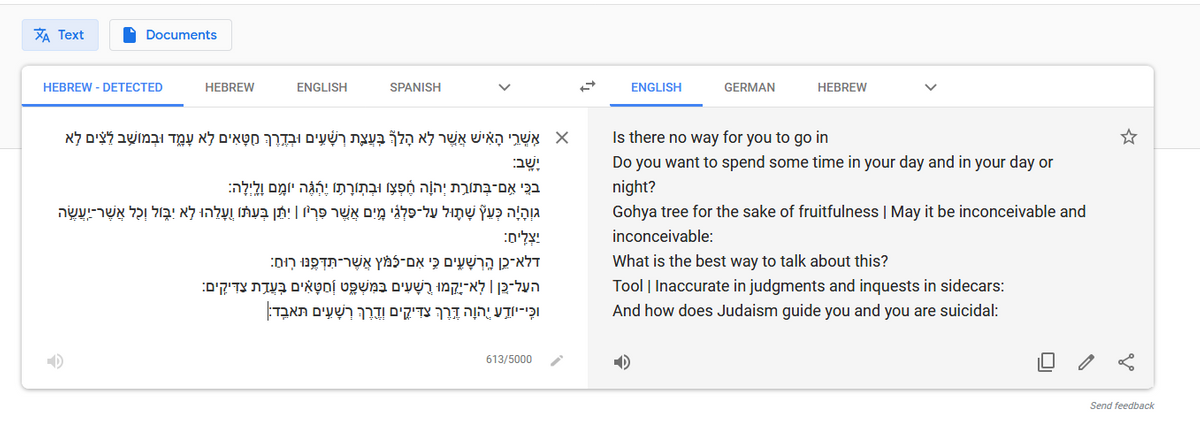
What does Google truly understand of this text, and what is just semantic trickery? Today, as machine learning depends on byzantine deep learning networks incomprehensible even to their own architects, the answer is fuzzy.
Franz Kafka wrote that Gregor Samsa woke up one day to find himself transformed into an ungeheures Ungeziefer. What he turned into in English has been a subject of great debate. Yet there is finally a consensus: He became an “enormous vermin.” This consensus, however, is only among the translation engines of Google, Microsoft, and Facebook, the most prominent and sophisticated machine translators available today. Are they right?
“Vermin” has been one of the most common choices among human translator but the choice of is debatable. Translator Susan Bernofsky, who translated Ungeziefer as “insect” in her sterling rendering, told me that “vermin” leads the reader off in the wrong direction: “In English you first think of rats and then cockroaches, while in German, Ungeziefer makes you think first of insects, then mice, and third or fourth of rats.”
However sophisticated the algorithms behind the latest translation engines used to translate Kafka are, they could not have gone through the sort of reasoning process Bernofsky describes in justifying “vermin.” The act of translating requires not only a fluency in language, Bernofsky argues, but a creative choice. For her, “all translation is writing.” One could add that a translator must be able to justify a particular translation—not irrefutably, but reasonably.
While computers have conquered chess and Go, games that few humans ever master, even the most advanced deep-learning algorithms can still be stumped by the language skills that every human picks up in the first years of life. It is a testament to the sheer complexity, holism, and functional imperfection of natural language that while computers can recognize faces and drive cars with skills comparable to those of humans, they still cannot engage us convincingly in conversation.
As Bernofsky implies, translation is as much about thinking as it is about language, and so machine translation is simultaneously one of the deepest and most elegant tests of a machine’s capacity to think. The texture of lived reality is formed not only by our interaction with objects but by the connections between concepts. This elusive quality of our world is thrown into direct relief by the problem of translation as it offers a profound but also unusually concrete measure of whether machines can replicate the subtleties of life as we humans experience it.
In 1960, Yehoshua Bar-Hillel wrote “A Demonstration of the Nonfeasibility of Fully Automatic High Quality Translation,” a pioneering work in the theory of machine translation. His elegantly made argument is that many texts will inevitably contain sentences “whose ambiguity is resolvable only on the basis of extra-linguistic knowledge which cannot be presumed to be at the disposal of a computer.” As an example, he gave, “The box was in the pen.”
Little John was looking for his toy box. Finally he found it. The box was in the pen. John was very happy.
The difficulty for machines is in recognizing that “pen” is a playpen, and not a writing implement—an inferential meaning that humans acquire intuitively through context. I tested Bar-Hillel’s example out on four leading translation engines, translating into French, German, Spanish, Polish, Portuguese, Italian, and Hebrew. Google gets it wrong across the board. Microsoft gets partial credit, correctly offering enclos in French and kojcu in Polish, but incorrectly giving pluma in Spanish, caneta in Portuguese, penna in Italian, Stift in German, and העט in Hebrew. Facebook got it right in Polish and wrong everywhere else, though it may deserve points for creativity in uniquely translating “pen” as בכלא (prison). And newcomer DeepL impressively got it right in French, German, Spanish, and Polish, but wrong in Portuguese and Italian (it doesn’t offer Hebrew). It would be helpful to understand just how DeepL managed this feat, but explanations are not in the offing.
When using machine-translation tools, Bar-Hillel concluded that a “post-editor” would be required to guarantee high quality translation, and despite some remarkable successes, his caveat still seems warranted. Moreover, there is something bizarre about the partial success: How is it that the same program could translate a word in the same sentence to have an entirely different meaning depending on the language selected?
To answer that question, we need to look at the guts of these programs. Up until the 1990s, computer translation worked through a crude approximation of human translation. Armed with a handcrafted arsenal of grammatical transformation rules and word and phrasal equivalents between two languages, translation programs would clunkily take a text in one language and render it in another. Results were almost uniformly poor.
But as computing power exponentially increased, a new field, statistical machine translation, emerged around 1990, which didn’t need to be fed rules, but instead attempted to pair up equivalent words and phrases across languages from a large sample of equivalent texts. Given thousands upon thousands of pages of texts in both Hebrew and English, statistical translators would find multiple possibilities for the translation of a particular phrase, statistically assess which one was “best” against its corpus, then pick the highest-ranking. Figuring out how to rank possibilities was the greatest challenge.
The results could still be disastrous: “I have a dog in the house” might go well into French or Spanish, but “I have a dog in this fight” requires the program to grasp the figurative sense of the phrase, since “Je n’ai pas de chien dans ce combat” only makes sense in French if you’re actually talking about dogs. Even today, I could not find any major machine-translation program that translated it as an idiom.
And this is because these programs do not possess “knowledge” in any substantive form. What they do possess are indicators of knowledge, in the form of countless numbers of texts across all human languages. Such corpuses, which barely existed 30 years ago, collect the many varieties of human expression in language—though some varieties are more present than others. Without the internet, the web, and 37 years of ever-increasing creation and digitization of natural language data by the world’s population, these programs could not function because they would lack a sufficiently large data set. Where a child can learn to speak simply by imitating their parents, this kind of machine translation requires instant access to thousands of years of textual data compiled in a global archive, just to take its first awkward steps toward language.
Where earlier generations of statistical translators operated on brute computing power and a quantity-over-quality approach, neural machine translation, the current vanguard, is more mysterious. Though the art and science of NMT is rather complicated, the goal is to build a system that grows and improves as it is given more parallel texts (and corrections to its own results). Like statistical machine translators, NMT frequently (but not always) begins from a library of existing comparable texts, such as the multilanguage corpus of European Parliament Proceedings. These texts are then used to train or condition a deep-learning network so that phrases and sentences passed into it result in, again, what the network thinks is the best possible translation.
NMT acts far more holistically than the older programs. The newer approach doesn’t require anywhere near the same amount of hand-tuning, yet produces, on average, better results—when judged by humans, at least. Much NMT, like neural networks more generally, works through a process of training. If older machine-translation approaches were akin to a person being handed a dictionary, phrasebook, and manual of grammar, NMT takes a step in the direction of how we learn language naturally, as children and adults: through the stumbling, iterative process of listening and observing and trial and error. The ability of NMT to translate, however flawed, is nonetheless uncanny.
The ironic thing about NMTs is that they are quite sensitive to nuance, just not in the way that humans are. What matters to them is syntactic and lexical nuance, so that even the slightest change in spelling or grammar can result in a different translation—without either the program or its programmers necessarily being able to explain why. For example, Google translates Kafka’s ungeheures Ungeziefer as “enormous vermin,” but if we use the rare spelling ungeheueres and put it in the dative case, Google turns ungeheueren Ungeziefer into “monstrous vermin,” the translation favored by Stanley Corngold and Joachim Neugroschel. Why the shift? Perhaps because that is the exact text in Kafka’s story, and Google’s NMT, ignorant of explicit grammar, case, and word relationships, may have chosen its translation of ungeheueren based primarily on parallel texts of The Metamorphosis itself. Or perhaps not—since the neural net algorithms “train themselves” based on the rules they’re given and data they are fed, they operate as black boxes, executing their tasks according to an internal logic that is unknowable even to their designers.
While NMTs are trained on parallel texts, Facebook went a step further by abandoning parallel texts altogether. Instead, they tried to find integral correlations between words across all languages—the goal being to create translation between languages where large amounts of parallel texts don’t already exist. The thinking goes: If the relationships between words within a language hold across different languages, it may be possible to infer translations from scratch.
In this example, Facebook’s researchers show how two languages, X and Y, could have the same abstract spatial relationship between their words for “cat,” “feline,” “car,” and “deep,” based on how those words tend to appear (or not appear) in relation to one another within each language.

The success of this approach suggests that such corresponding relationships may indeed exist across languages. Yet undoubtedly they do not exist for some words and idioms, and as with our original case of Kafka’s insect, “Ungeziefer” and “insect” cannot correspond so precisely, even if we allow that “cat” and “gatto” might.
Consider the example of the Ma Nishtana, the first question of Passover. For the Hebrew:
מַה נִּשְׁתַּנָּה, הַלַּיְלָה הַזֶּה מִכָּל הַלֵּילוֹת
Google gets quite close to the traditional English translation: “Why is this night different from all the other nights?”—likely due to having been provided with parallel texts of this exact sentence. Facebook, however, offers the more literal but less accurate, “What will change, this night of all nights?” as “change” loses the emphasis on the “differentness” of the night that is central to the question’s meaning.
The failure of literalness in the example of the “Ma Nishtana” suggests something essential about the relationship between language and meaning. The meaning of words is embedded not only in the language in which they are used but in larger social contexts, which, for some, includes layers of metaphysical and religious resonance. Even careful and learned human translators can miss some of these levels of meaning. The master modern translator of the Torah, Robert Alter, in his book, A Literary Approach to the Bible, contrasts other 20th-century biblical translators with the religious Torah scholars of the past. “The difference between the two is ultimately the difference between assuming the text is an intricately interconnected unity, as the midrashic exegetes did, and assuming it is a patchwork of frequently disparate documents, as most modern scholars have supposed,” Alter writes. Without endorsing all of their beliefs, Alter’s point is that the midrashic rabbis’ religious worldview gives them a greater “literary” sensitivity to the Torah’s meaning, than is found in most modern biblical scholars. “With their assumption of interconnectedness, the makers of the Midrash were often as exquisitely attuned to small verbal signals of continuity and to significant lexical nuances as any ‘close reader’ of our own age.”
In fact, we can think of machine translation more generally as being more literal and less accurate than human translation. The paradox of NMT is that by creating a landscape of the relations of each word to every other word, it takes a step toward holism without grasping the level of semantic meaning. As the Facebook example shows, the relationships between all words within a language can potentially impact any translation it performs. But these relationships are still assessed by machines without any sense of how language is used in relation to the world. To determine whether a pen is a writing device or a prison can perhaps be gleaned from comparing word usages across thousands and thousands of texts, but this is not the way humans make such a determination, because we are trained by the experience of using language against a world that accepts or rejects our language.
“This entire notion of ‘machine translation’ is based on what I think is a false notion of equivalence between languages, the notion that every language expresses something similar in comparable terms,” says Bernofsky. Rather, the word-to-word (or, on occasion, phrase-to-phrase) parallelism of machine translation suggests that language itself is being simplified and stripped down, for these translation engines are not just descriptive but prescriptive, and the equivalencies they produce will reinforce themselves as language evolves, standardizing and flattening meaning.
One side effect is the diminishing of the individual histories of words within languages, so long as they show some dominant parallel with one particular word in another language. Ungeziefer will become vermin and vermin alone. Kafka himself presciently hit on this issue in 1914 when he introduced a recital of Yiddish poetry by observing,
Yiddish cannot be translated into German. The links between Yiddish and German are too delicate and significant not to be torn to shreds the instant Yiddish is transformed back into German, that is to say, it is no longer Yiddish that is transformed, but something that has utterly lost its essential character. If it is translated into French, for instance, Yiddish can be conveyed to the French, but if it is translated into German it is destroyed. “Toit” for instance, is not the same thing as “ tot” (dead), and “ blut” is far from being “blut” (blood).
Our global interconnectedness has resulted in these sorts of delicate and significant links being increasingly made between all languages, and yet these links are precisely what machine-translation programs smooth over when finding verbal equivalents.
Whether translating a Yiddish song or ancient Hebrew, the remarkable progress of machine translation also helps to illustrate what is being left out. Even the most complex NMT methods still operate in a fundamentally homogenizing manner, working from the assumption that word and phrasal equivalents exist locally regardless of context. To draw a parallel with rabbinic interpretation, it is as though NMT is jumping to the more allusive and structural practices of remez and derash, searching for connections and parallels, without having yet grasped peshat, the core meaning of a particular text in its particular context. The results may be stunning, but there remains a hole at their core.
David Auerbach is the author of Bitwise: A Life in Code (Pantheon). He is a writer and software engineer who has worked for Google and Microsoft. His writing has appeared in The Times Literary Supplement, MIT Technology Review, The Nation, Slate, The Daily Beast, n+1, and Bookforum, among many other publications. He has lectured around the world on technology, literature, philosophy, and stupidity. He lives in New York City.









